
این آزمایش نشان میدهد که راهی مستقیم برای عبور از قانون «اولین لینک مهم است» با استفاده از اصلاح لینکها وجود ندارد اما امکان انجام این کار با استفاده از ایجاد ساختاری از لینکها بر اساس جاوا اسکریپت وجود دارد. این مقاله نوشته یکی از نویسندگان مهمان سایت سرچ انجین لند است.

در تالارهای گفتگوی اینترنتی و گروههای محتوا محور فیسبوکی، اغلب بحثهایی پیرامون نحوه کارکرد رباتهای گوگل (که به طور مخفف GB نامیده میشوند)، آنچه آنها میتوانند و نمیتوانند مشاهده کنند، انواع لینکهای قابل بازدید و تاثیر توسط آنها بر سئو وجود دارد.
برای بهینه سازی سایت خود از دپارتمان خدمات سئو نوین مارکتینگ مشاوره سئو بگیرید؛ این مشاوره رایگان است.
در این مقاله، نتایج آزمایشی سه ماهه، که توسط خودم انجام شده است را به اطلاع شما خواهم رساند. در سه ماه گذشته من ربات گوگل را همه روزه شبیه به یک دوست میدیدم.
گاهی اوقات ربات تنها بود:
و ما فرصت زیادی برای انجام انواع بازیها داشتیم:
کش: من مشاهده میکردم که ربات گوگل چگونه از مسیرهای ریدایرکت 301 میگذرد، تصاویر را کراول میکنند و وارد مسیرهای مختلف میشود.
زنده ماندن: من موانعی با درجات سختی مختلف طراحی کردم تا برخورد دوست کوچکم را با آنها بررسی کنم.
همانطور که ممکن است شما هم بگویید، من ناامید نشدم. ما زمان زیادی را با هم خوش گذراندیم و به دوستان خوبی برای هم تبدیل شدیم. به نظر من دوستی ما آیندهای درخشان خواهد داشت.
اما بهتر است که به سراغ اصل مطلب برویم.
من وبسایتی با محتوای شاخص محور برای یک آژانس مسافرتی فضایی برای سفر به سیارات ناشناخته در کهکشان راه شیری و سایر کهکشانها ساختم.
محتوای ارائه شده حجم زیادی از شاخصها را در خود داشت اما در واقع مطالب آن همگی بیمعنی بودند.
ساختار وبسایت مورد آزمایش به صورت زیر بوده است:
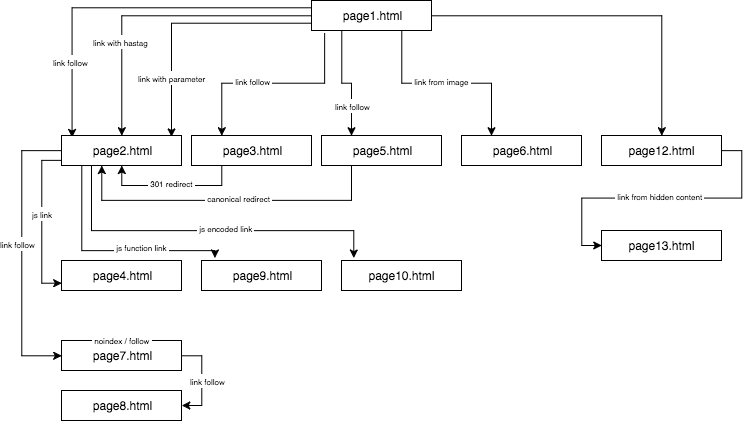
من محتوایی منحصر بهفرد تهیه کردم و از تمامی نشانهگذاریهای ممکن نظیر انکرتکست، عنوان و متن جایگزین تصویر یا تگ alt را در کنار مواردی کاملاً منحصر بهفرد (کلمات اشتباه) استفاده کردم. برای سادهتر شدن مطالعه محتوا برای بازدید کننده، در بخش توضیحات از اسامی افراد که اغلب سخت هستند استفاده نکردم و به جای آن anchor1 و غیره را به کار بردم.
به شما پیشنهاد میکنم که در حین مطالعه این مقاله، نقشه فوق را در یک زبانه جداگانه باز کنید.
ضمنا اگر ربات های گوگل و نحوه عمل آن ها را نمیشناسید حتما مقاله سایبورگ سئو در نوین مارکتینگ را بخوانید آن مقاله در درک بهتر متن حاضر بسیار کمک رسان است.
از اینجا بخوانید : معرفی الگوریتم برت ، گوگل به دنبال درک بهتر زبان طبیعی است
1- اولین لینک برای ربات گوگل اهمیت دارد
یکی از چیزهایی که من میخواستم در این آزمایش سئو امتحان کنم، قانون “اولین لینک اهمیت دارد” بود. آیا میتوان به این قانون استناد کرد و تأثیر آن بر بهینهسازی چگونه است؟
قانون “اولین لینک اهمیت دارد” میگوید که در یک صفحه، ربات گوگل فقط اولین لینک به یک زیر صفحه خاص را مشاهده میکند. اگر شما دو لینک به یک زیرصفحه در صفحه خود داشته باشید، بر اساس این قانون لینک دوم نادیده گرفته میشود. ربات گوگل متن همراه لینک دوم را نیز نادیده میگیرد و هیچ تأثیری در محاسبه رتبه صفحه شما نخواهد داشت.
این مشکلی است که توسط بسیاری از متخصصان سئو مشاهده شده و یکی از مواردی است که در فروشگاههای آنلاین بسیار شایع است، زیرا منوی ناوبری این سایتها، ساختار اصلی وبسایت را تغییر میدهد.
در اکثر فروشگاهها، منویی ایستا (استاتیک) قابل مشاهده در کدهای صفحه وجود دارد که به عنوان مثال 4 لینک به دستههای اصلی و 25 لینک مخفی در زیر آن به زیردستهها وجود دارد. در حین بررسی ساختار صفحه، ربات گوگل همه لینکها (در هر یکی از صفحههای دارای منو) را مشاهده میکند که در یکسانسازی اهمیت صفحات در حین مشخصسازی و توان آنها در نمایش اثرگذار است، موضوعی که به صورت زیر بیان میشود:
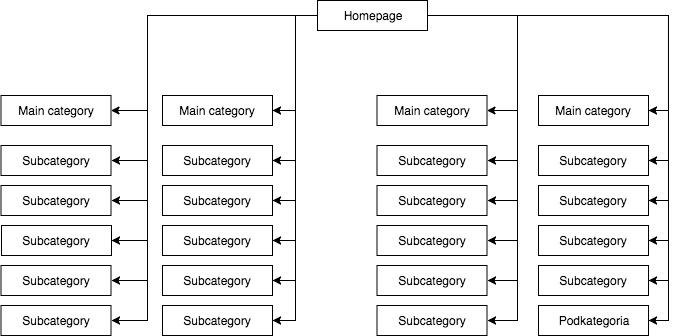
رایجترین و البته به نظر من اشتباهترین ساختار صفحه.
مثال بالا را نمیتوان ساختاری مناسب برای سایت در نظر گرفت زیرا تمامی دستهها در تمامی صفحات سایت که دارای منو هستند، لینک شدهاند. از اینرو هم صفحه نخست و هم صفحات دسته و زیردستهها، لینکهای ورودی یکسانی دارند و قدرت کل وبسایت به طور یکسان میان آنها پخش شده است. بنابراین قدرت صفحه نخست (که به طور معمول به دلیل تعداد لینکهای ورودی منبع اصلی قدرت سایت است) به 24 دسته و زیردسته تقسیم میشود. پس هر یک از صفحات فقط 4 درصد قدرت صفحه اصلی را دارند.
ساختار بایستی چگونه به نظر برسد:
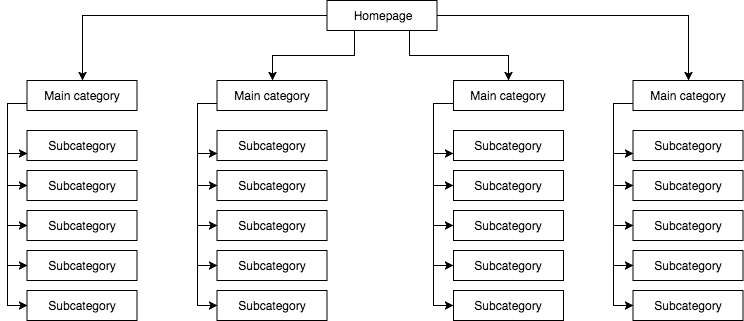
اگر به آزمایشی سریع برای بررسی ساختار صفحه خود و خزش آن به مانند گوگل نیاز دارید، Screaming Frog ابزاری عالی برای شما است.
در این مثال، قدرت صفحه نخست به 4 دسته تقسیم میشود و هر یک از دستهها 25 درصد از قدرت آن را به خود اختصاص داده و در زیر دستهها پخش میکنند. این راهکار شانس بیشتری برای لینکدهی داخلی فراهم میکند. برای مثال وقتی که شما مقالهای در وبلاگ فروشگاه مینویسید و یکی از زیردستهها را لینک میکنید، ربات گوگل در حین خزش سایت شما این لینک را مشاهده میکند. در مورد اول اما به دلیل قانون اولین لینک اهمیت دارد، این کار را انجام نمیداد. اگر لینک دهی به یک زیر دسته در منوی وبسایت باشد، لینکی که در مقاله آورده شده است نادیده گرفته میشود.
من این آزمایش سئو را با انجام کارهای زیر آغاز کردم:
- نخست در صفحهی html لینکی به زیر صفحه page2.html با دستور dofollow و متن anchor1 قرار دادم.
- در ادامه در متن همان صفحه، لینک دیگری به صفحه دوم قرار دادم تا بررسی کنم که ربات گوگل آن را خزش میکند یا نه.
برای پایان کار، راهکارهای زیر را آزمایش کردم:
- در صفحه نخست، لینکی برای یک عبارت حاوی نشانی اینترنتی (هر لینک خارجی با هر متنی که به صفحه نخست و زیرصفحه اشاره کند) قرار دادم. این کار سرعت ایندکس شدن سایت را افزایش میدهد.
- منتظر ماندم تا صفحه html هم برای متنی که در لینک صفحه اول آورده شده بود (anchor1) رتبهبندی شود. این عبارت اشتباه و یا هر عبارت دیگری که من بررسی کردم در صفحه هدف قابل مشاهده نبود. پس از 45 روز به این نتیجه رسیدم که در این حالت اگر هر یک از لینکهای مربوط به صفحهی 2 کار میکرد، این صفحه برای آنها رتبه بندی میشد و در نتایج جستجو قابل مشاهده بود. حالا میتوانستم اولین نتیجهگیری مهم خود را مشاهده کنم.
حتی وبسایتی که نه از کلمات کلیدی در محتوا و نه در عنوان متا استفاده کرده است، با استفاده از یک لینک با متن عالی میتواند به راحتی در نتایج جستجوی گوگل بالاتر از وبسایتی با محتوای دارای آن عبارت اما بدون لینک به کلمهی کلیدی قرار بگیرد.
به علاوه، صفحه نخست (Page1.html) که عبارت اصلی را در خود داشت، قویترین صفحه سایت بود (در 78 درصد زیر صفحهها لینک شده بود) اما با این حال رتبه کمتری نسبت به عبارت مربوطه در زیر صفحه (Page2.html) کسب کرده بود.
در ادامه من 4 مورد از روشهای لینک کردن را که استفاده کرده بودم، خواهم آورد. همه این موارد پس از اولین لینک dofollow به صفحه Page2.html آورده شدهاند.
لینک به یک وبسایت همراه با متن
< a href=”page2.html#testhash” >anchor2< /a >
اولین لینک افزوده شده در کدنویسی که بعد از لینک اول آورده شده است، لینکی با یک متن (یک هشتگ) است. من میخواستم که برخورد ربات گوگل با لینک و حرکت در مسیر آن را مشاهده کنم. این که آیا ربات گوگل بدون توجه به اینکه لینک به صفحه 2 میرود اما نشانی اینترنتی به هشتگی در این صفحه تغییر یافته است، صفحه 2 را برای عبارت انکر2 ایندکس میکند یا نه.
متأسفانه ربات گوگل هرگز این ارتباط را مشاهده نکرد و این کار قدرت صفحه 2 را برای عبارت فوق افزایش نداد. در نتیجه، در صفحه نتایج مربوط به جستجوی عبارت anchor2 فقط یک نتیجه مشاهده میشود که آن هم مربوط به صفحه 1 است، جایی که این عبارت به عنوان متن لینک آورده شده است. حتی با جستجوی عبارت testhash (هشتگ مورد آزمایش) نیز نتیجهای برای صفحه دوم مشاهده نمیشود. پس میتوان نتیجه گرفت درج هشتگ در صفحات اچ تی ام ال و وبسایت ها فعلا هیچ تأثیری ندارد.
لینک به یک وبسایت همراه با یک پارامتر
page2.html?parameter=1
در آغاز، ربات گوگل به این بخش جالب از نشانی اینترنتی که دقیقاً بعد از نشانه عبارت و در درون متن لینک (anchor3) آمده بود، علاقه نشان داد.
در ادامه ربات گوگل در تلاش بود تا منظور من را بفهمد. فکر میکنم که ربات از خودش میپرسید که «آیا این یک معما است؟» برای پرهیز از ایندکس شدن محتوای تکراری با نشانیهای اینترنتی دیگر، مسیر Page2.html را به گونهای طراحی کردم که به خودش اشاره کند. نتایج لاگها نشان میدهد که صفحه با این نشانی 8 بار خزیده شده است، نتایج حاصل عبارتند از:
- بعد از دو هفته، تعداد دفعات بازدید ربات گوگل از این صفحه به شدت کاهش مییابد تا اینکه در نهایت ربات این صفحه را فراموش کرده و دیگر از آن بازدید نمیکند.
- html نه برای عبارت anchor3 و نه برای parameter1 ایندکس نشده است. بر اساس نتایج کنسول جستجو، این لینک وجود ندارد (در لینکهای ورودی نیز به حساب نیامده است)، اما همزمان با این موضوع، عبارت anchor3 به عنوان عبارت لینک فهرست شده است.
لینک به یک وبسایت با استفاده از بازنشانی یا ریدایرکت
من میخواستم که ربات گوگل را به ایندکس کردن وبسایتم مجبور کنم، برای انجام این کار، یک روز در میان لینکی dofollow را با متن لینک anchor4 به صفحه 1 اضافه میکردم که به صفحه page3.html منتهی میشد، البته در این فرآیند از کد بازنشانی 301 به Page2.html استفاده کردم. متأسفانه، مشابه حالتی که برای مورد قبلی پیش آمد، پس از 45 روز صفحه 2 در نتایج گوگل برای عبارت anchor4 رتبهبندی نشد اما در بخش لینکهای بازنشانی شده Page1.html نمایش داده شد.
به هر حال در کنسول جستجوی گوگل، در بخش متون انکر، anchor4 قابل مشاهده بود و ایندکس نیز شده بود. این موضوع نشان میدهد، همانطور که انتظار میرفت، بعد از مدتی بازنشانی شروع به کار میکند. در نتیجه Page2.html بدون در نظر گرفتن این که لینک دوم به صفحه مشابه در سایت مشابه میرود، در نتایج مربوط به anchor4 نمایش داده خواهد شد.
لینک به یک وبسایت با استفاده از تگ کانونیکال
در صفحهی 1 ارجاعی به Page5.html (لینک دنبالپذیر) قرار دادم که متن آن anchor5 بوده است. همزمان صفحه Page5.html محتوایی منحصربهفرد دارد و در عنوان آن تگ کانونیکالی به صفحه Page2.html قرار دادم.
< link rel=“canonical” href=”https://example.com/page2.html” />
نتایج این آزمایش به شرح زیر است:
- لینک مربوط به عبارت anchor5 به صفحه Page5.html به طور کانونیکال به صفحه 2 بازنشانی میشود و به صفحه هدف نمیرود (درست مثل سایر موارد فوق).
- Page5.html بدون توجه به تگ کانونیکال ایندکس شده است.
- Page5.html برای عبارت anchor5 در نتایج جستجو ردهبندی نشده است.
- Page5.html برای عبارت استفاده شده در متن صفحه رتبه بندی شده است که نشان میدهد ربات گوگل به طور کلی تگهای کانونیکال را در نظر نگرفته است.
من قویاً میتوانم اعلام کنم که استفاده از rel=canonical برای پیشگیری از ایندکس کردن بخشی از محتوا (مثلاً هنگام فیلتر کردن) کارایی ندارد.
بخش دوم: بودجه خزش
هدف من در هنگام طراحی راهبرد سئو این بود که ربات گوگل به ساز من برقصد و نه برعکس آن! برای دستیابی به این منظور، من پردازشهای سئو را در سطح لاگهای سرور (لاگهای دسترسی و خطا) بررسی کردم که برتری بسیار بزرگی را برای من به ارمغان آورد. به لطف این کار، از همه حرکات ربات گوگل و نحوه تعامل آن با تغییراتی که من در کمپینهای سئو ایجاد میکردم (ساختاربندی سایت، تغییر سیستم لینکدهی داخلی سایت و شیوه نمایش اطلاعات) آگاه میشدم.
یکی از اهداف من در کارزار سئو بازسازی وبسایت بر مبنای شیوهای بود که ربات گوگل فقط نشانيهایی را بازدید کنند که قابل ایندکس بودند و من میخواستم که ایندکس کنند. به طور خلاصه: صفحاتی وجود دارند که از نقطه نظر سئو برای ایندکس شدن در گوگل اهمیت دارند. از سویی دیگر ربات گوگل بایستی فقط وبسایتی را خزش کند که ما میخواهیم در گوگل ایندکس شود، این موضوعی است که برای همه واضح نیست. برای مثال، زمانی که یک فروشگاه آنلاین فیلتر بر اساس رنگ، اندازه و قیمت را با تغییر پارامترهای نشانی اینترنتی انجام میدهد، به عنوان مثال:
example.com/women/shoes/?color=red&size=40&price=200-250
این کار ممکن است که راهکاری باشد برای اینکه به ربات گوگل اجازه دهد نشانیهای وب را به صورت پویا خزش کند تا زمان بیشتری برای بررسی (و احتمالاً ایندکس) آنها به جای خزش صفحات داشته باشد.
example.com/women/shoes/
چنین نشانیهای اینترنتی پویا، نه تنها بیاستفاده هستند، بلکه برای سئو نیز مضرند، زیرا ممکن است به عنوان محتوای کمحجم در نظر گرفته شوند که نتیجه آن کاهش رتبه سایت خواهد بود.
همچنین با انجام این آزمایش، به دنبال این بودم که چند روش ساختاردهی بدون استفاده از rel=”nofollow”، مسدود کردن دسترسی ربات گوگل به فایل robots.txt یا قراردادن بخشی از کد html در قابی که فقط برای ربات در دسترس باشد (Blocked iFrame) را نیز امتحان کنم.
من سه نوع مختلف از لینکهای جاوا اسکریپت را آزمایش کردم.
لینک جاوا اسکریپت با رویداد کلیکی
یک لینک ساده در جاوا اسکریپت به صورت زیر است:
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html’” >anchor6< /a >
ربات گوگل به راحتی میتواند به زیرصفحه Page4.html برود و کل صفحه را ایندکس کند. زیر صفحه در نتایج جستجو برای عبارت anchor6 رتبه بندی نمیشود و عبارت در بخش متون انکر کنسول جستجوی گوگل نیز قابل یافت نیست. نتیجه این است که این لینک قابلیت انتقال قدرت را ندارد.
به طور خلاصه:
- یک لینک جاوا اسکریپت کلاسیک به گوگل اجازه میدهد که وبسایت را خزیده و صفحات آن را ایندکس کند.
- این کار قدرت را منتقل نمیکند که البته طبیعی است.
لینک جاوا اسکریپت همراه با تابع داخلی
من به دنبال آزمونهای سختتر بودم اما بر خلاف انتظار من، ربات گوگل 2 ساعت بعد از انتشار لینک بر من غلبه کرد.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
برای راه اندازی این سایت، از یک تابع داخلی استفاده کردم که برای خواندن دادههای حاصل از نشانی اینترنتی و بازنشانی آنها (فقط بازنشانی یک کاربر) به صفحه هدف Page9.html بود. مشابه حالت پیشین، این صفحه به طور کامل ایندکس شد.
نکته جالب توجه این بود که هر چند لینکهای داخلی برای این صفحه وجود نداشت اما Page9.html، پس از Page1.html و Page2.html، سومین صفحه پر بازدید توسط ربات گوگل در تمامی سایت بود.
من قبلاً هم از این روش برای ساختاردهی یک وبسایت استفاده کرده بودم. به هر حال، همانطور که مشاهده میشود، این روش کارایی ندارد. در سئو، به جز صفحات زرد، هیچ چیز همواره کارایی ندارد.
لینک جاوا اسکریپت همراه با کدنویسی
من هنوز تصمیم به تسلیم شدن نداشتم و فکر میکردم که باید راهی کاربردی برای بستن راه بر ربات گوگل وجود داشته باشد. بنابراین یک تابع ساده را طراحی کردم که در آن دادهها با الگوریتم base64 کدنویسی شده و عبارت آن به صورت زیر است:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
نتیجه این کار این بود که ربات گوگل نتوانست کد جاوا اسکریپتی بسازد که هم محتوای نشانی وب را بازنویسی کند و هم صفحه را بازنشانی کند. این نتیجهای است که میخواستیم! ما راهی پیدا کردیم که یک وبسایت را بدون استفاده از تگ rel=nofollow برای جلوگیری از خزش همه لینکها، ساختاربندی کنیم! با این روش بودجه خزش خود را هدر نمیدهیم، موضوعی که خصوصاً در وبسایتهای بزرگ اهمیت دارد و در نهایت ربات گوگل به ساز ما میرقصد. چه تابع در بخش سرصفحه همان صفحه قرار داده شود و چه در یک فایل جاوا اسکریپت (JS) جداگانه، هیچ نشانی از ربات گوگل، نه در لاگهای سرور و نه در کنسول جستجو مشاهده نمیشود.
3.محتوای مخفی
در آخرین آزمایش، به دنبال بررسی این مورد بودم که آیا محتوای مخفی موجود در یک زبانه توسط ربات گوگل دیده شده و ایندکس میشود یا به ادعای برخی از کارشناسان، گوگل این صفحه را همانطور که مشاهده میشود میخواند و محتوای مخفی را در نظر نمیگیرد.
من به دنبال رد یا تأیید این ادعا بودم. برای انجام این کار، دیواری از متن با بیش از 2000 لغت را در Page12.html قرار دادم و آن را با استفاده از روش Cascading Style Sheets و دکمه نمایش بیشتر، پشت محتوایی بسیار کمتر (400 لغتی) مخفی کردم. همچنین در متن مخفی شده، لینکی به صفحه Page13.html با متن anchor9 قرار دادم.
شکی وجود ندارد که یک ربات میتواند صفحه را بخواند. ما این موضوع را هم در کنسول جستجوی گوگل و هم در بخش بررسی سرعت گوگل مشاهده کردهایم. با این وجود آزمایش من نشان داد که مجموعهای از متن که پس از کلیک روی دکمه مشاهده بیشتر نمایش داده میشود به طور کامل ایندکس شده است. عبارت مخفی شده در متن، در نتایج جستجو رتبه بندی شده بود و ربات گوگل لینکهای مخفی در آن را دنبال کرده بود. به علاوه، متن مربوط به لینک موجود در بخش مخفی، در قسمت متون انکر کنسول جستجوی گوگل قابل مشاهده بود و صفحه Page13.html نیز برای کلمه کلیدی anchor9 رتبه بندی شده بود.
این موضوع برای فروشگاههای آنلاین حیاتی است، زیرا محتوای آنها اغلب در زبانههای مخفی قرار میگیرد. حالا ما مطمئنیم که ربات گوگل محتوای زبانههای مخفی را میبیند، آنها را ایندکس میکند و اعتبار ناشی از لینکهای موجود آنها را هم انتقال میدهد.
مهمترین نتیجهگیری من از این آزمایش این است که من راهی مستقیم برای دور زدن قانون اولین لینک اهمیت دارد با استفاده از اصلاح لینکها (لینکهای دارای پارامتر، بازنشانی 301، کانونیکال و لینکهای انکر) پیدا نکردم. در همین حین امکان ایجاد ساختار وبسایتی که از لینکهای جاوا اسکریپت استفاده میکند وجود دارد که میتواند محدودیت قانون اولین لینک اهمیت دارد را دور میزند. به علاوه، ربات گوگل میتواند محتوای مخفی را ببیند و ایندکس کرده و لینکهای موجود در آن را دنبال کند.
توصیه نهایی ما به شما این است که اگر می خواهید از تابعهای جی اس یاد شده در این مقاله استفاده کنید حتما جانب احتیاط را در نظر گرفته با تست چند باره بر روی سایت خود آنها را به کار ببندید.




